In today’s world of distributed systems, data moves fast, and applications need to handle huge volumes of data in real time. Whether you’re building microservices, integrating external systems, or managing streaming data, ensuring smooth communication between data producers and consumers is crucial. This is where Apache Kafka comes in—a powerful event streaming platform that enables scalable and decoupled data exchange.
A Beginner’s Guide to Apache Kafka: Event Streaming Made Easy
I’m Daniel Hirsch, a software engineer based in Germany, and in this post, I’ll share insights from my exploration of Apache Kafka, helping you understand its core concepts and how it solves common problems in modern software architectures.
Instead of reading this blog post, you can also consume (hehe, Kafka pun intended) the content on YouTube: Apache Kafka Introduction (in under 20 minutes)

What Problem Does Kafka Solve?
In many applications, there’s a need for different services to communicate by sending and receiving data. For example, a weather app might have a sensor (a data producer) sending temperature data, while the app’s interface (a data consumer) displays that data in real time. As your application grows, so does the number of data producers and consumers, leading to an explosion of connections between them.
This tightly coupled communication model is not scalable. You’d have to maintain custom APIs for each connection, making it difficult to change or expand your system. Kafka solves this by providing a centralized platform for managing data exchange between services—decoupling producers and consumers and allowing them to operate independently.
Understanding Event Streaming
At its core, Kafka facilitates event streaming, a method for real-time processing of continuous streams of data. Think of Kafka as a cupboard with drawers—each drawer stores a specific type of information. Data producers (services like sensors or user interfaces) add information to these drawers, and data consumers (such as databases or analytics systems) retrieve the information.
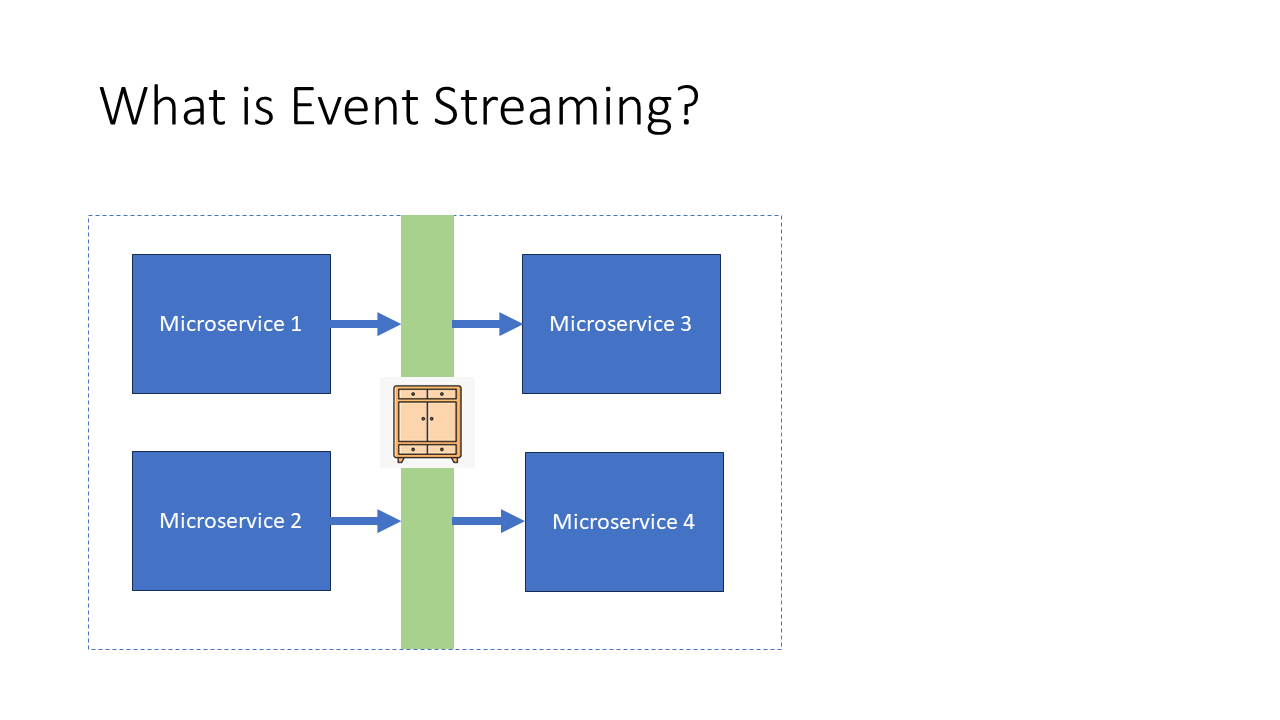
Instead of services directly talking to each other, they simply produce or consume data from Kafka. This means that services don’t need to know about each other’s existence, and they can work independently, which simplifies system architecture and scaling.
Kafka’s Key Components
Let’s break down the fundamental components of Kafka:
-
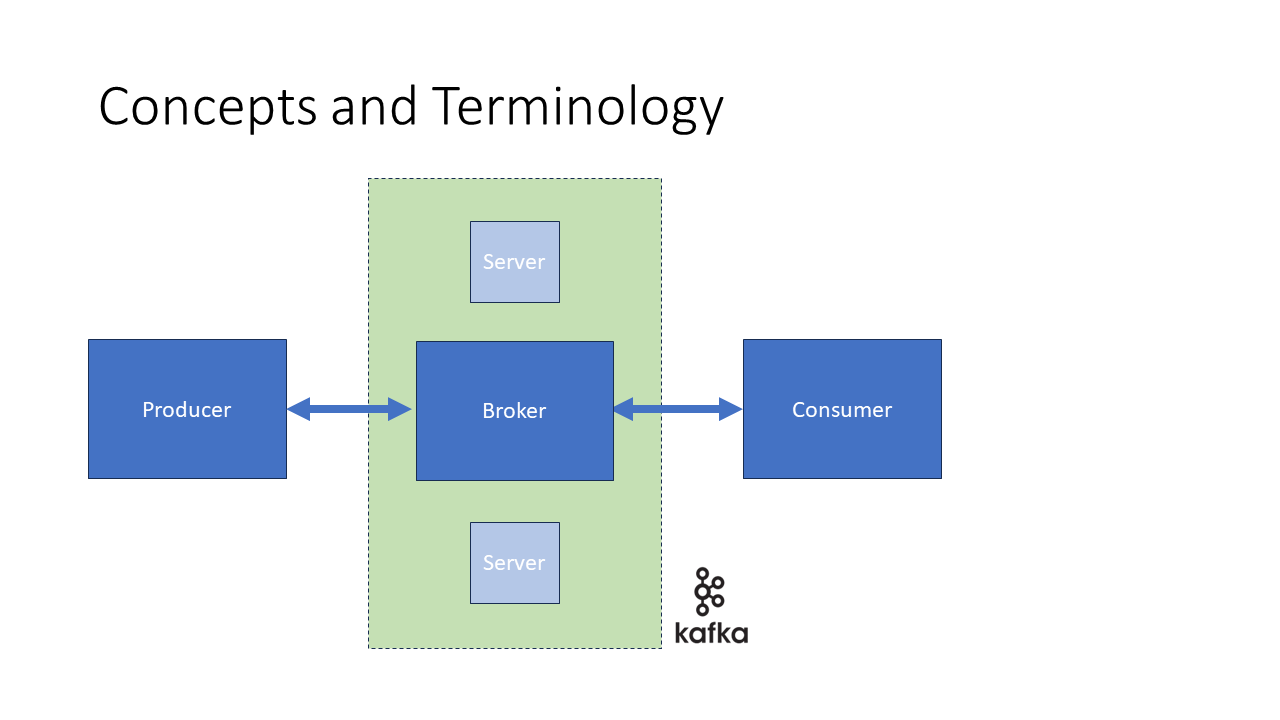
Brokers: These are the servers (or a cluster of servers) that store and manage data streams. Brokers handle incoming data from producers and distribute it to consumers. You can have multiple brokers in a Kafka cluster, which ensures fault tolerance and scalability.
-
Producers: These are services or systems that generate data. For example, a producer could be a sensor sending weather data or a user posting a message on a social media platform. Producers send data to a specific Kafka topic.
-
Consumers: These are the services or applications that read and process data. For instance, a consumer might be a database that stores weather data for future analysis, or an application that displays real-time social media posts.
-
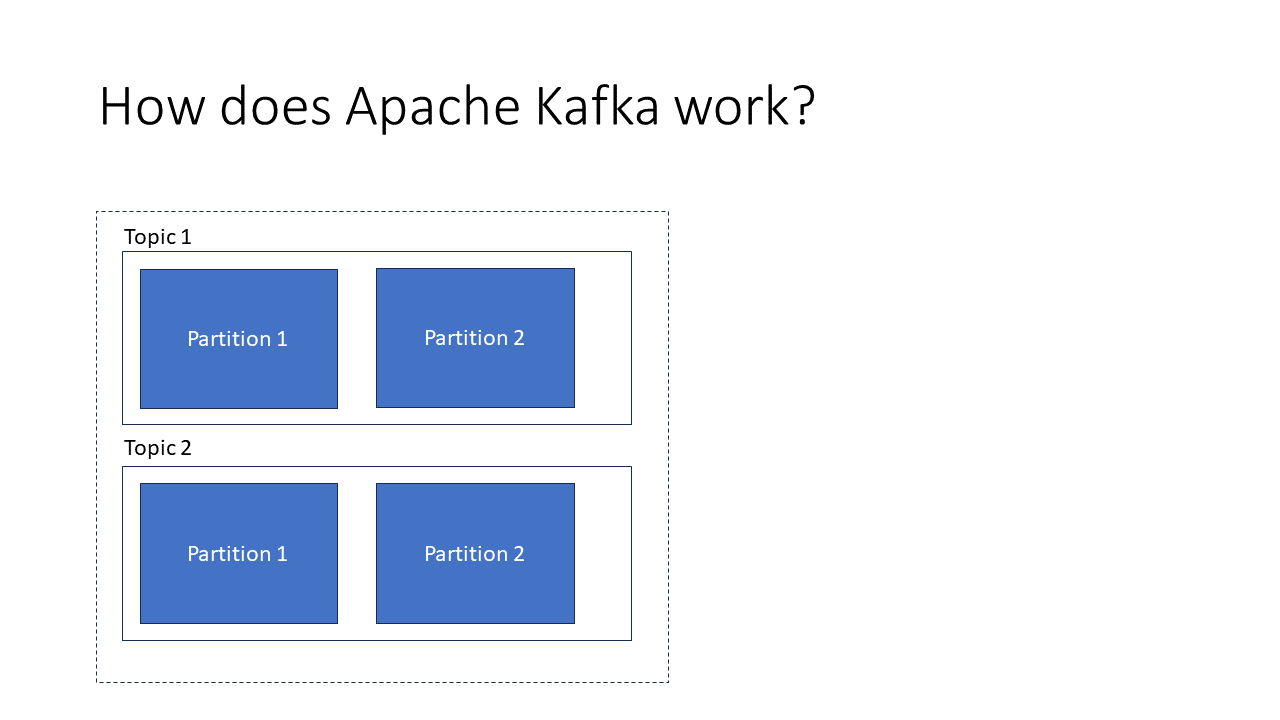
Topics: Topics are Kafka’s way of organizing data. Each topic represents a category of data, such as “weather data” or “user messages.” Producers write to topics, and consumers read from topics. This separation ensures data is well-organized, and consumers can subscribe to relevant topics based on their needs.
-
Partitions: Kafka splits topics into partitions, which are smaller, more manageable chunks of data. Partitions enable parallel processing, allowing multiple producers and consumers to handle data simultaneously. For example, a topic for user messages might be partitioned by the first letter of the user’s name, ensuring that different partitions can be processed independently.
- Events: In Apache Kafka, an event represents a record of data, typically composed of a key, value, timestamp, and metadata. Events are central to Kafka’s message streaming architecture, as they are the units of data that flow between producers and consumers. Producers send events to Kafka topics, where they are stored and managed in partitions.
A small dive into the structure of events
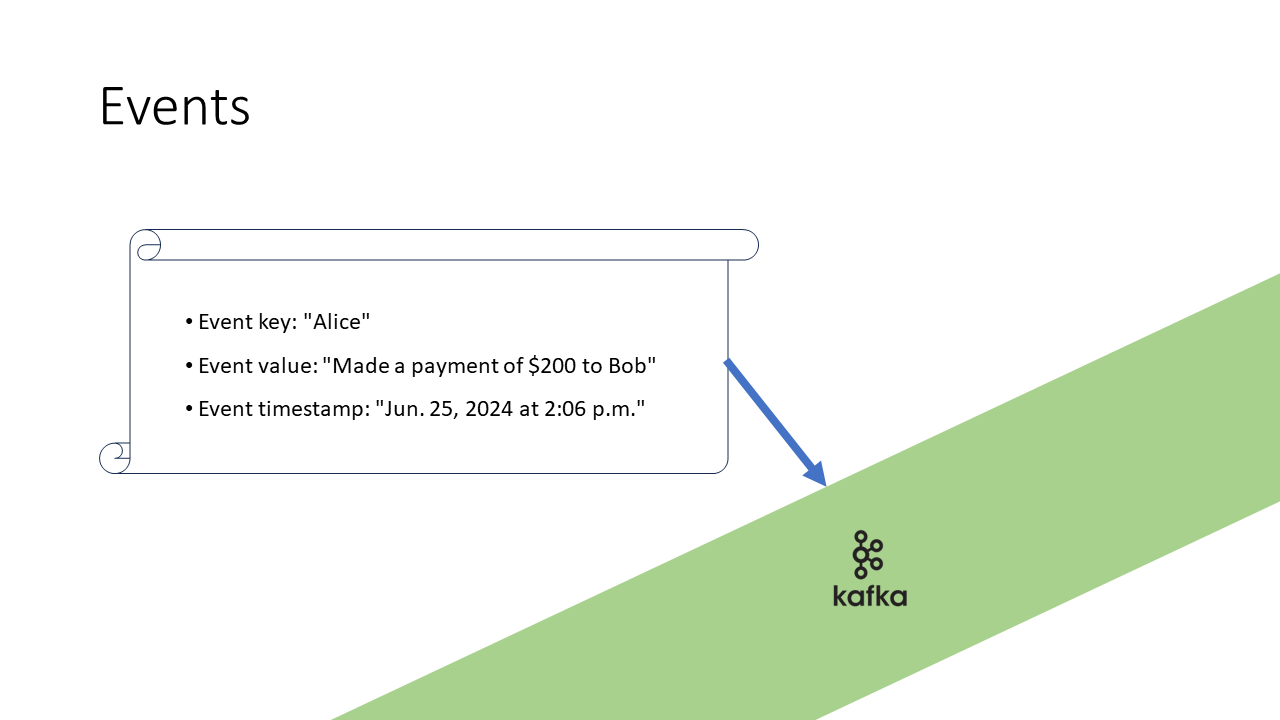
A typical event example in Kafka might look like:
- Key: Identifies the event, such as a user ID.
- Value: The actual data payload, for instance, “Alice sent $200 to Bob.”
- Timestamp: The time the event was created or processed.
Events are immutable, meaning they can only be appended to topics but not modified once written. This ensures a consistent and reliable stream of data that can be consumed by different services independently and in parallel. By decoupling producers and consumers, Kafka allows for scalable, distributed, and fast processing of events across systems.
How Kafka Handles Data
When a producer writes data to a Kafka topic, it doesn’t just throw everything into one big pile. Instead, data is appended to a partition in the topic, like adding files to a specific folder. This log-based structure allows Kafka to handle large volumes of data efficiently.
As producers write new events to a partition, Kafka keeps track of the index of each event. Similarly, when a consumer reads data, it keeps track of the last index it read, ensuring it doesn’t miss any new data. This sequential access to data means Kafka avoids many of the performance issues found in traditional databases, like memory fragmentation or slow random access.
Producers write data and track the index
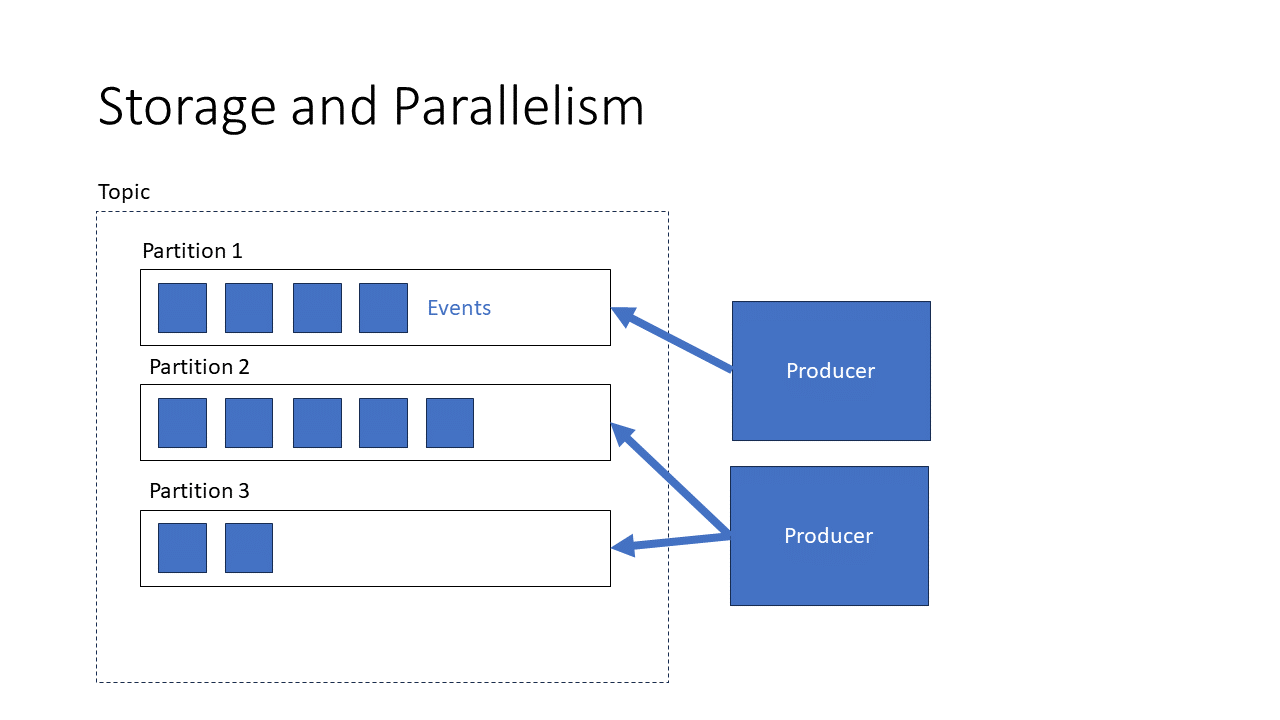
Data is always appended to a partition. Never ever does Kafka insert data into the middle of a partition or even modify a log.
Consumers read data and track their index
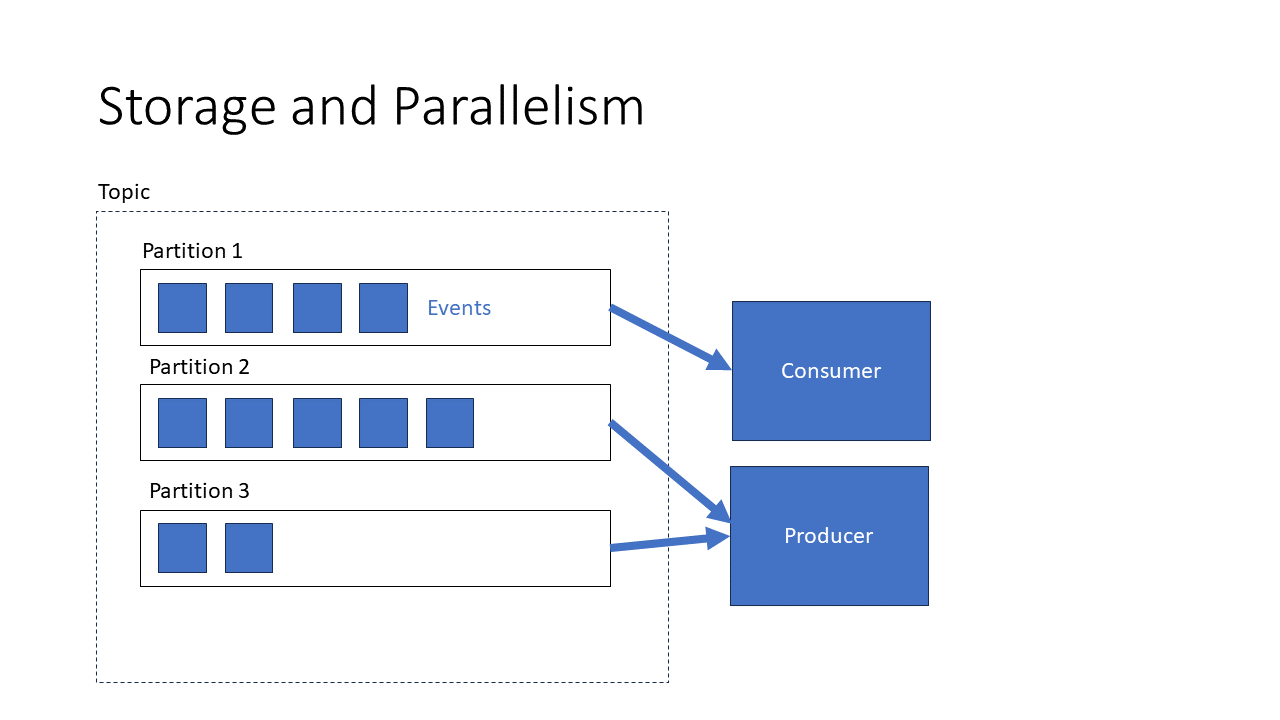 Data is always read sequentially, meaning that the pointer index pointing at a memory location moves incrementally. Never does it jump from memory location to memory location!
Data is always read sequentially, meaning that the pointer index pointing at a memory location moves incrementally. Never does it jump from memory location to memory location!
Why Kafka Is Fast and Scalable
Kafka’s strength lies in its distributed, decentralized architecture. Instead of relying on a single server to store and process data, Kafka allows you to use multiple brokers. Each broker handles a portion of the data, and if one broker goes down, another can take over, ensuring no data is lost.
By partitioning topics and distributing them across brokers, Kafka also ensures high throughput. Producers can write to different partitions at the same time, and consumers can read from multiple partitions simultaneously. This parallelism enables Kafka to handle millions of events per second, making it ideal for large-scale, real-time applications.
Conclusion
Apache Kafka is a powerful tool for modern applications that need to process and manage vast amounts of real-time data. By decoupling producers and consumers and providing a scalable platform for event streaming, Kafka simplifies the architecture of distributed systems and ensures data flows smoothly, even in the most demanding environments.
If you’re building applications that need to handle continuous streams of data efficiently, Kafka is definitely worth considering. I hope this introduction helped clarify how Kafka works and why it’s so widely used in the world of event streaming. Stay tuned for more in-depth posts, and feel free to explore Kafka further on your own!